
柯洁输掉了与AlphaGo的第一战。而在对战前的深夜,柯洁在社交网络上发布了一篇题为《最后的对决》的文章,充满了易水诀别般的悲壮感,其中写道:“现在的AI进步之快远超我们的想象……我相信未来是属于人工智能的。”引发王思聪在评论区质问:“哟,当时李(世石)和AlphaGo下的时候你那嚣张劲儿去哪儿去了?”
2016年3月,在韩国棋手李世石以1:4不敌李世石后,这位少年得志的天才棋手确实曾在微博上撂下豪言“阿尔法狗胜得了李世石,胜不了我”,成为超级网红。
虽然人类棋手在过去的一年里努力地研究AlphaGo的套路,试图找到AlphaGo的弱点,但其实,AlphaGo也早已完成更新换代,今非昔比。柯洁在赛后发布会上表示,AlphaGo和去年判若两“狗”,去年它的下法还很接近人类,现在感觉越来越接近“围棋上帝”——围棋中永不失误的完美境界。
AlphaGo之父、DeepMind创始人戴密斯·哈萨比斯(Demis Hassabis)也在当天的赛后发布会上承认,之前与李世石交手的AlphaGo还是有一些漏洞的,他们在过去的一年里全力完善算法,弥补漏洞。
那么,现在的AlphaGo到底发生了哪些改变?AlphaGo的研发公司DeepMind是如何升级它的?5月24日上午,在中国乌镇人工智能高峰论坛上,哈萨比斯和AlphaGo团队负责人Dave Silver(戴夫·席尔瓦)揭晓了新一代AlphaGo的奥秘。
深度强化学习:降低搜索树的宽度和深度。本文图片均来自 澎湃新闻记者 王心馨
这次柯洁面对的AlphaGo大师版,和去年李世石面对的AlphaGo李版主要有三大不同:首先,AlphaGo大师版摈弃人类棋谱,单纯向AlphaGo李版的经验学习;其次,AlphaGo大师版的计算量只有AlphaGo李版的十分之一,只需在单个TPU机器上运行;最后,AlphaGo大师版拥有更强大的策略网络和价值网络。
要理解AlphaGo的算法,首先要从1997年击败国际象棋神话卡斯帕罗夫的“深蓝”算法说起。国际象棋的每一步都会引出下面三十种可能的走法,棋局的走向就和一棵不断分出三十个分杈的大树一样。而“深蓝”所做的,就是检索完这棵大树上的所有分杈,找出当下最优的那一步。“深蓝”的计算能力因此能达到每秒1亿个位置,是那个时代的突破性产物。
但到了围棋这里,这种蛮力计算是不可行的。围棋的每一步牵出的后续选择有数百种。这么庞大的搜索树是无法被穷举的。哈萨比斯说道,比起解构性的象棋,围棋是个建构性的游戏,也更依赖直觉,而非单纯的计算。
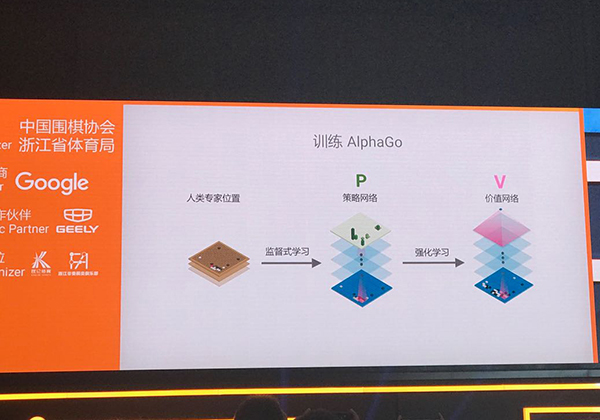
而AlphaGo就依赖两个网络来简化这棵庞大的搜索树:降低搜索树宽度的策略网络和降低搜索树深度的价值网络。
席尔瓦介绍道,AlphaGo李版首先运用策略网络进行深度学习,将大量人类棋谱输入其中,根据人类经验排除掉搜索树上一部分的分杈。也就是说,虽然围棋当前的每一步都有上百种可能性,但根据人类经验,只有一部分是好的选择,AlphaGo只需要搜索这些分杈,另一些根本就是“臭棋”。
然后,AlphaGo也不需要在这些分杈上一路搜索到底,模拟到棋盘结束才知道当前这步棋的优劣。在当前某个特定的选择往下,AlphaGo只模拟几步,就能得出一个分数。这个数值越大,AlphaGo获胜的概率就越高。那么,这个数值是怎么得出的呢?这就要靠价值网络进行强化学习。
在强化学习中,AlphaGo就根据策略网络推荐的走法自我对弈,左右互搏,在经过反复自我训练,积累了大量数据之后,AlphaGo就能更快地对当前走法的胜率有一个概念。
策略网络和价值网络配合形成的深度强化学习,虽然不能提高AlphaGo的计算能力(事实上,AlphaGo每秒计算1万个位置,远低于“深蓝”),但却能让AlphaGo更“聪明”地计算。
AlphaGo自学成才:上一代是下一代的老师
而这次柯洁面对的AlphaGo大师版,比起去年李世石面对的AlphaGo李版,最大的不同是在深度学习环节,使用的大量训练数据并非人类棋谱,而是AlphaGo李版自我对弈的数据。


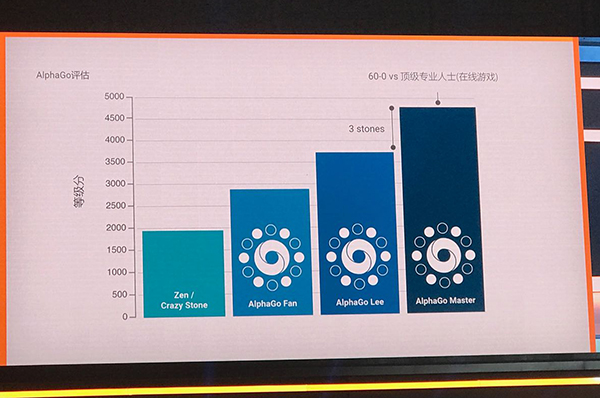
AlphaGo大师版对比AlphaGo李版三大升级。
席尔瓦说道:“AlphaGo大师版能如此高效运算的最主要原因是,我们使用了最好、最可用的数据来训练它。我们所说的最好的数据不是来自于人,而是来自于AlphaGo自己。AlphaGo现在等于说是自学成才。我们让它自己当自己的老师,而这一代的AlphaGo也会成为下一代AlphaGo的老师。”
汲取了大量自我学习的经验,这次与柯洁交手的AlphaGo大师版的策略网络和价值网络也因此更为强大。这大大提高了AlphaGo的运算效率 ,把计算量缩减到对战李世石时的十分之一。从硬件来看,AlphaGo李版在下棋时还需要50个TPU(谷歌专为加速深层神经网络运算能力而研发的芯片),AlphaGo大师版现在和柯洁对战时只需要1个TPU。
而更强大的AlphaGo大师版又会带来更优秀的数据,以训练下一代AlphaGo。这是一个良性循环。
AlphaGo的迭代增强。
哈萨比斯说道,AlphaGo的首要目标还是要“追求完美”。在过去的数千年,人类都没有达到围棋的真理境界。他希望,AlphaGo能和人类共同努力,趋近围棋真理。
[责任编辑:郭晓康]

 京ICP证130248号京公网安备110102003391
京ICP证130248号京公网安备110102003391